The Benefits of Data Substrate Architecture

In the previous article, we discussed the details of some of the architecture design of Data Substrate. In this article, we continue the discussion and elaborate on why we made these design choices and how these choices affect the resulting database solutions we built.
Thread Per Core Execution Model and Async I/O

The Data Substrate adopts a thread-per-core execution model, a strategy well-aligned with modern multicore hardware. In this model, each core is assigned a dedicated thread that manages a variety of tasks using cooperative multitasking, eliminating the overhead of frequent context switches. This design ensures high CPU cache locality, reduces synchronization complexity, and enables fine-grained control over task scheduling. By minimizing contention and maximizing predictable performance, the thread-per-core model lays the foundation for building scalable and efficient distributed systems.
In Data Substrate, the thread serves as the primary unit of abstraction, with data partitioned and processed independently by each thread. Inter-thread communication is handled exclusively through message passing, and synchronization is limited to lightweight producer-consumer queues. This design intentionally reduces reliance on shared memory within a server node, allowing threads to operate in isolation and avoid contention. Specialized threads are designated for tasks like RPC handling and storage access, but beyond that, threads remain largely self-contained. This approach not only reflects best practices for building high-performance single-node applications but also provides a clean and natural path for scaling out to distributed deployments.
To ensure responsiveness and efficient resource utilization, all potentially blocking operations in Data Substrate are handled asynchronously. By leveraging modern OS capabilities like io_uring, the system performs network and storage I/O without stalling worker threads. This asynchronous model is critical for managing latency in I/O-bound workloads, a common characteristic of databases. With non-blocking operations, regular worker threads can remain active and productive, eliminating idle CPU cycles and maintaining high throughput even under heavy load.
In Data Substrate, each thread is designed to fulfill multiple roles—it may execute operations while also managing one or more CCMap shards. When a thread needs to access data and it happens to manage the shard containing the target entry, it can skip message passing altogether and access the memory directly, achieving maximum efficiency for local operations. This optimization demonstrates one of the core principles of the Data Substrate design, which is to enable zero overhead in degraded modes of operation: if a distributed feature isn't required, it should not impose any performance penalty. In this case, such optimization ensures that no additional overhead is incurred when the system operates in a non-distributed, single-threaded configuration. A direct consequence of this design is the performance characteristics of EloqKV. When performing in-memory data access (i.e. when WAL and data store is disabled), its per-core performance is close to Redis, which is a single threaded implementation. In a multi-threaded setup, its performance is close to DragonflyDB, a modern purpose-built multi-threaded in-memory KV store with Redis API.
Decoupling of Compute, Memory, Log and Data Store
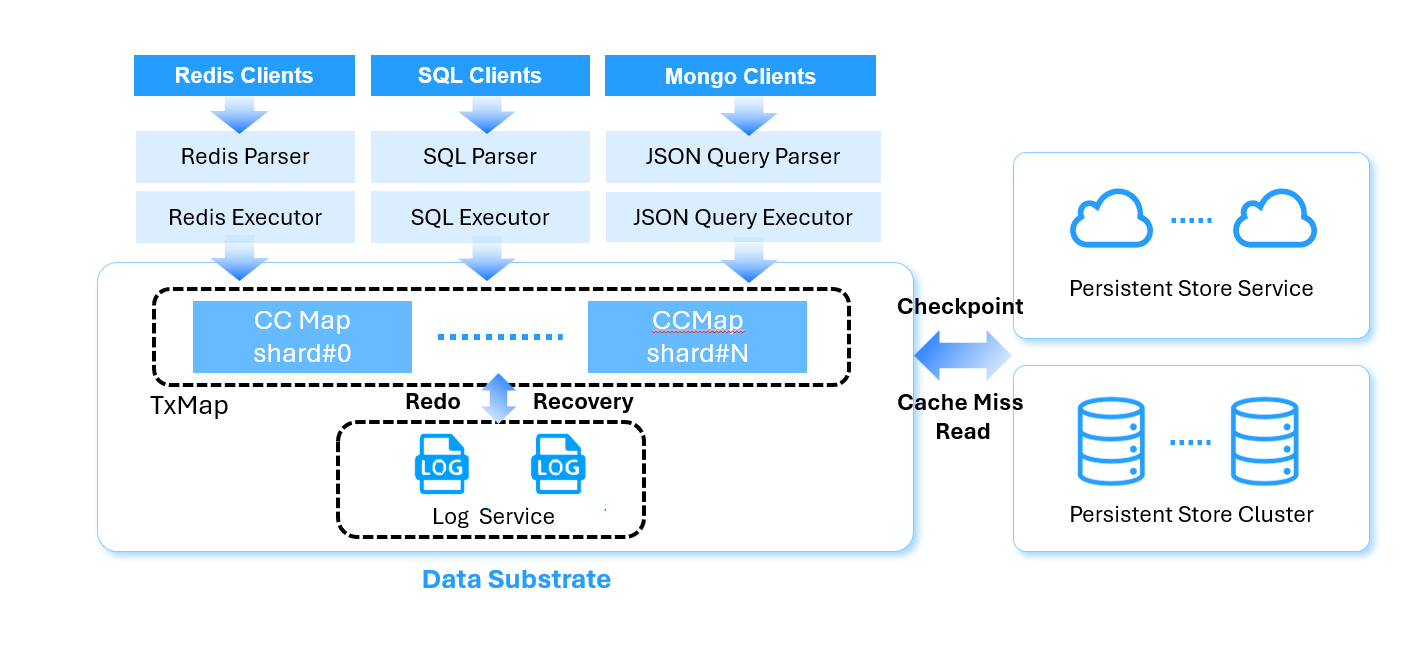
Data Substrate achieves a high degree of modularity by decoupling compute, logging, and storage into separate threads, each responsible for its own function. This separation allows for clean isolation of responsibilities and avoids cross-component interference. While the current implementation may allow a thread to handle both query computation and buffer management, the architecture is designed such that these roles can be fully separated. The message-passing model abstracts away physical locality, enabling threads to interact seamlessly whether they reside on the same server or across the network. As a result, each subsystem can scale independently, allowing the system to adapt dynamically to changing workload patterns.
This decoupling is a foundational principle of the Data Substrate design, enabling the independent scaling of four critical resource types: compute (CPU cycles for query execution), memory (used as dirty data buffer and cache for hot data), logging (governing write throughput and durability latency), and storage (backing data capacity and cache miss performance). In cloud environments where resource provisioning is granular and on-demand, this separation offers a significant architectural advantage. It allows the system to allocate only the resources needed for a given workload, avoiding over-provisioning and improving both cost efficiency and operational flexibility.
Moreover, this architectural decoupling enables dynamic scaling—resources can be added or removed at runtime without interrupting ongoing operations. This is particularly powerful in cloud-native deployments, where workload patterns can shift rapidly and unpredictably. Data Substrate is designed to respond to these changes by elastically adjusting compute, memory, logging, and storage resources on demand. To our knowledge, it is the only database architecture that supports independent dynamic scaling of all four resource types, offering a level of elasticity and adaptability that traditional monolithic systems cannot match. (Note: dynamic scaling of logging is still under development.)
Share Everything Architecture
Traditionally, the shared-nothing architecture has been the dominant model for building scalable distributed databases. In this approach, each server node operates as an independent unit with its own dedicated compute, memory, and storage resources. While this simplifies certain aspects of distribution, it also introduces rigid boundaries—when a node fails, its local data and state become immediately inaccessible, potentially disrupting the system. Moreover, dynamically scaling, though possible, is tedious and time consuming, since migrating data between servers often takes hours or even days. In contrast, modern cloud-native designs like Amazon Aurora adopt a shared-storage model, where data is stored independently from compute, allowing read replicas to be dynamically launched to handle fluctuating read workloads. This separation of data and storage introduces greater elasticity and fault tolerance but remains limited in certain aspects. For example, to avoid the overhead of distributed transactions, shared-storage system only allows a single writer node, and the readers generally can only see stale state.
Data Substrate takes a different approach by embracing a share-everything architecture, where every thread can access and interact with the full system state, regardless of its physical location. This is a deliberate departure from the traditional share-nothing and share-storage model.
In the share-everything model adopted by Data Substrate, each thread functions as an autonomous unit, capable of operating independently while still having access to the global system state. This abstraction simplifies system design by removing rigid node boundaries and enables a highly elastic and fault-tolerant architecture. Developers can think of programming Data Substrate as programming a large single-node machine, where the primary challenge is handling the failure and recovery of individual threads. When a thread fails, it is responsible for reconstructing its own state by replaying logs and retrieving data from the durable storage layer, ensuring that fault recovery is localized, efficient, and minimally disruptive to the rest of the system.
Of course, making a distributed system behave like a single computer requires careful handling of a number of complex challenges, such as avoiding split-brain scenarios and ensuring consistent state across failures. Fortunately, decades of research in distributed systems have produced a rich set of techniques to address these problems. Consensus protocols like Paxos and Raft ensure agreement among nodes, while replication protocols maintain data consistency and durability. Lease and failure detection mechanisms help coordinate access and detect faults promptly. Data Substrate builds on these foundational techniques, integrating them into its architecture to provide the illusion of a unified system while preserving the robustness and safety required in a truly distributed environment.
One common concern when treating a distributed system as a single large computer is data locality, which traditionally has a major impact on performance due to network latency and bandwidth limitations. However, in modern cloud environments, high-speed datacenter networks with sub-millisecond latency and multi-gigabyte bandwidth have significantly reduced this bottleneck. While data locality still plays an important role in optimizing performance, it is no longer a strict constraint. In a share-everything architecture like Data Substrate, data locality is a matter of policy rather than a concern for correctness. By adjusting policy to restrict thread placement and scheduling, Data Substrate can effectively mimic shared-nothing or shared-storage architectures as needed.
With Data Substrate, building a database on top of a shared-everything distributed "computer" becomes a natural extension of decades of work on single-node database systems. This architecture allows us to reuse well-understood mechanisms for concurrency control and recovery, while adapting them to operate in a distributed context. For instance, databases on Data Substrate can support a range of isolation levels—read committed, repeatable read, serializable or MVCC and snapshot isolation—just as traditional systems do. While higher isolation levels may carry greater performance costs on a large scale, their correctness remains straightforward to reason about. Thanks to the clean separation of concerns in the Data Substrate design, low-level distributed system challenges like node crashes and restarts are isolated from database-level logic, making the system easier to reason about, maintain, and extend.
Auto Scaling and Scale To Zero
In the context of cloud-native databases, features like auto scaling and scale to zero have become essential for optimizing cost and performance, with support now seen in systems such as Neon and AWS Aurora. Auto scaling enables a database to dynamically adjust compute resources in response to workload fluctuations—scaling up during peak demand and scaling down when load decreases—without manual intervention. Scale to zero takes this a step further by releasing compute and memory resources entirely when the system is idle for a certain duration. Upon receiving new workload, the system can rapidly rehydrate and begin processing within seconds. This approach dramatically improves cost efficiency, as users incur charges primarily for persistent storage when the database is not actively in use, aligning resource usage directly with actual demand.
Historically, implementing auto scaling and scale-to-zero has been challenging due to the tight coupling of compute and storage in traditional database architectures. In such systems, compute nodes typically manage in-memory caches, transaction state, and local storage, making it difficult to release or reassign resources without interrupting availability or risking data loss. The emergence of decoupled cloud storage changes this equation—by separating persistent data from compute, databases can now shed or acquire compute and memory resources.
Databases built on top of Data Substrate can implement auto-scaling with minimal complexity, thanks to the system's inherently decoupled architecture. Since compute, memory, storage, and logging are managed independently, a lightweight monitor process can dynamically allocate or release compute and memory resources—typically as containers or VMs—based on current workload demands. In a cloud environment, the storage (such as S3 or DynamoDB) are generally regarded as fully scalable. Last but not least, as an independent service in Data Substrate, the logging service can easily spin up more logging devices to allow better write throughput and reduce write latency as needed. As far as we know, the databases built on top of Data Substrate, such as EloqKV, EloqSQL and EloqDoc are the only family of distributed databases that can independently scale all four types of resources.
As for scale-to-zero, when the database becomes idle, the monitor instructs it to take a final checkpoint, flush any in-memory state to durable storage, truncate the logs, and cleanly shut down the active components. Upon the return of workload, a new container can be launched, quickly recover the last state from storage, and resume processing with little to no delay—making this process efficient, cost-effective, and operationally seamless.
Object Storage as Primary Data
A major trend in the cloud computing era is the widespread adoption of object storages such as Amazon S3 as the primary data store, driven by their compelling advantages in cost, durability, and scalability. While object storage was initially considered slow, this perception has changed with the evolution of software architecture that can effectively hide or amortize latency. OLAP systems were early adopters—databases such as Snowflake, and open formats like Apache Iceberg, support high-performance analytical processing on top of S3. The movement has since expanded beyond analytics: StreamNative's Ursa engine uses S3 as its core storage layer for streaming data, Confluent launched Freight Clusters to adopt a similar model. Even vector and full-text search engines, like Turbopuffer, are embracing object storage to decouple compute from data and support elastic scaling.
However, using object storage as the primary data store introduces non-trivial latency, which, while tolerable for OLAP workloads and asynchronous, event-driven architectures, becomes a bottleneck for OLTP systems that require consistently low-latency responses. This is why most OLTP databases still avoid relying directly on object storage. In cloud environments, fast and cost-effective NVMe storage is often available on virtual machines, offering excellent performance characteristics—but this storage is ephemeral and tied to the lifecycle of the VM, meaning all data is lost if the VM is terminated. As a result, most OLTP databases today rely on services like Amazon EBS (Elastic Block Store), which provide durable, VM-independent storage. EBS can be reattached to a new VM after a failure, ensuring data durability, but this reliability comes at a cost—particularly when high throughput or low-latency IOPS are required, making it an expensive choice for performance-critical applications.
Database systems built on top of Data Substrate are uniquely positioned to take full advantage of object storage without suffering its typical drawbacks. Thanks to Data Substrate's decoupled architecture, S3 can be used as the primary data store to absorb the bulk of data capacity, while durability is jointly ensured by both the Log and the Data Store, as detailed in our previous post. Logging—which demands low-latency, durable writes—can be handled by a small EBS volume, since logs are mostly append-only and frequently truncated. This minimizes cost while preserving reliability. Updates to the data store happen at checkpointing time, when dirty CCMap entries are cleaned. Therefore, updates are performed in batches and asynchronously, meaning they do not block critical paths and can be safely written to S3 in the background. Meanwhile, local ephemeral NVMe storage can serve as a high-performance cache for read operations, absorbing cache misses efficiently. By orchestrating these three tiers—object storage for capacity, EBS for durability, and NVMe for performance—Data Substrate achieves a balanced, cost-effective storage strategy that leverages the strengths of each medium while avoiding their respective limitations.