A Deeper Dive Into Data Substrate Architecture

In this article, we dive deeper into the technical foundations of Data Substrate—highlighting the key design decisions, abstractions, and architectural choices that set it apart from both classical and modern distributed databases.
Introduction
In traditional database systems, scale and consistency often come at the cost of complexity, rigidity, or degraded performance. At EloqData, we've taken a fundamentally different approach. Data Substrate reimagines the database as a unified, distributed computer—where memory, compute, log and storage are fully decoupled yet globally addressable. In a previous article, we explored the motivations and core inspiration behind this architecture. Today, we dive deeper into its technical foundations—highlighting the key design decisions, abstractions, and architectural choices that set Data Substrate apart from both classical and modern distributed databases. While this article is not exhaustive, we aim to offer a clear, grounded view of how Data Substrate works and why it matters. For those interested in exploring further, visit our GitHub repositories or join our Discord community.
A Retrospect Overview of Existing Database Designs
Database systems have evolved over many years, and the canonical design remains the single-node, multi-threaded (or multi-process, in the case of e.g. PostgreSQL) architecture, as described in numerous textbooks. This classical design typically includes a page buffer manager for handling in-memory state, a lock manager for concurrency control, a Write-Ahead Log (WAL) for durability, and a B-Tree based data store for managing on-disk pages. These components collectively make up the state management layer of the database. Above this layer, the execution engine—which includes a SQL parser, query optimizer, and query execution engine—interacts with users and translates their requests into operations on the state management layer of the database.
As mentioned in our previous blog post, the Data Substrate design is heavily inspired by the textbook single-node database architecture. However, before diving into its specifics, it's important to examine the limitations of the traditional approach and the solutions that have emerged to address them.
One of the major challenge is scalability: classical designs rely on vertical scaling—using larger, more powerful machines—and do not support horizontal scaling across multiple servers, which severely limits their ability to grow with increasing workloads.
To handle data that cannot fit in a single server, various approaches have been proposed. The simple method is database sharding, by partitioning the database into multiple smaller database shards and split the workloads to be handled by multiple single-node databases. An example is the Vitess/PlanetScale approach that leverages multiple MySQL instances. While database sharding allows systems to scale out, it introduces significant operational complexity, often requiring manual planning, rebalancing, and custom tooling. Moreover, it offers poor support for cross-shard transactions and queries, which can lead to inconsistencies, degraded performance, or the need for complex coordination protocols that are hard to maintain and debug.
The alternative to database sharding is data sharding—building a truly distributed database system and distribute data among server nodes. However, this approach is inherently complex, particularly when it comes to supporting ACID transactions across distributed nodes. Many NoSQL systems like MongoDB and DynamoDB in the beginning chose to forgo strong consistency to simplify this challenge, offering eventual consistency instead. Though later versions of these systems almost always added ACID support, famously pointed out by a recent paper. NewSQL databases such as CockroachDB and TiDB, on the other hand, often adopt designs inspired by Google's Percolator or Spanner, layering distributed transactions over an underlying key-value store using protocols like two-phase commit. While this enables stronger consistency, it typically comes with substantial overhead, resulting in significantly lower per-node performance compared to well-optimized single-node databases.
In recent years, shared-storage databases like Amazon Aurora and Neon (now part of Databricks) have gained traction in the market. These systems offer virtually unlimited storage and support multiple read replicas, but they remain constrained by a single write node, which imposes fundamental limits on write scalability. Additionally, the read replicas often serve stale data due to replication lag, making them less suitable for workloads requiring strong consistency. This architecture also struggles when the hot data working set exceeds the memory capacity of a single node, causing performance degradation.
Another limitation of the classical single-node database design is the tight coupling between on-disk data storage and in-memory data representation. Historically, page–based B-trees have dominated as the primary on-disk storage format, leading many traditional databases to manage memory in terms of pages as well. This close coupling makes it difficult to support alternative data models like graphs or streams, which may require different memory and storage abstractions. While newer systems have adopted techniques like LSM trees to address some of these challenges, legacy systems such as MySQL and PostgreSQL remain largely constrained by their page-based memory architectures. Moreover, many storage related issues, such as garbage collection of free pages, are coupled with concurrency control of the databases or the query execution engines, making it difficult to swap out storage, adopt new concurrency control algorithms, or add new data models. In short, many of the existing databases are not cleanly modularized.
In this article, we discuss how EloqData's Data Substrate architecture addresses these issues.
Scalability and the CCMap
As mentioned earlier, the Data Substrate architecture draws inspiration from classical single-node database design, but introduces key innovations to support diverse data models and enable true scalability.
One of the foundational changes lies in the redesign of the buffer pool. Instead of a traditional page-oriented buffer pool, we introduce an in-memory–optimized structure called the TxMap—a large, sharded key-value map. Each entry in the TxMap consists of a key-value pair, abstracting away the specific data model. The key could represent a page ID in a relational system, a node ID in a graph, or a timestamp in a time-series database, while the corresponding value might hold a page's content, a graph node's adjacency list, or a time-series payload. This abstraction allows the upper-layer computing engine to interact with data uniformly, regardless of the underlying model.
The TxMap is divided into multiple shards, each called a CCMap, or Cache and Concurrency control Map. A CCMap holds a subset of the TxMap's entries and is responsible not only for storing data but also for managing concurrency control metadata such as row-level locks. It tracks modification timestamps and marks entries as dirty when they have been updated. Crucially, each CCMap is exclusively accessed by a single thread, eliminating the need for latches and enabling highly efficient operations. Interactions with a CCMap entry are performed through message passing to the thread that owns the shard, ensuring safe and scalable concurrency management.
This abstraction provides a powerful foundation for scalability by offering a uniform mechanism for accessing sharded data through CCMaps. When a thread needs to access a data item, it simply issues a request to the corresponding CCMap, without needing to know whether the target shard resides on the local machine or a remote one. This decoupling allows the system to scale across multiple machines transparently.
Decoupling of Logging and DataStore
Unlike many distributed database designs that adopt a "shared nothing" architecture, Data Substrate embraces a "shared everything" approach, treating the entire distributed system as a single, unified computer. In this model, the TxMap functions as a large, distributed memory accessible by any thread, regardless of where the data physically resides. In addition to TxMap, Data Substrate introduces two other major components: the logging service and the data store. These components are designed to be decoupled and shared across the system, enabling flexible coordination and efficient resource utilization at scale.
The logging service in Data Substrate fulfills largely the same role as the Write-Ahead Log (WAL) in traditional single-node databases, but it is reimagined for distributed environments. Unlike the monolithic WAL of classic systems, Data Substrate supports multiple distributed logging devices, each functioning as a durable, recoverable log accessible by any thread during recovery. Log durability is ensured either through replication or by leveraging highly reliable services such as AWS EBS.
When a thread needs to persist log entries during transaction execution, it can write to any available logging device. To maintain global order among distributed log entries—a critical requirement for consistency—traditional distributed databases often rely on external timestamp services (like time oracles) or specialized hardware (such as Spanner's atomic clock based truetime). Data Substrate, by contrast, adopts a hybrid approach that combines Hybrid Logical Clocks (HLC) with a TicToc-inspired time-travel mechanism to assign globally ordered timestamps. Because recovery threads can access all log devices, the system can reliably reconstruct the state of the database during failures. This flexible, decentralized logging model not only enhances fault tolerance but also improves scalability by avoiding bottlenecks associated with centralized log (and timestamp) coordination.
As in traditional single-node databases, a transaction in Data Substrate is considered committed once its WAL entry has been successfully written. The effects of the committed transaction are then applied to the in-memory buffer (i.e., the TxMap), marking certain entries as dirty. To manage memory usage, these dirty entries must be periodically checkpointed to a persistent data storage engine. Once checkpointing is complete, the corresponding log entries can be safely truncated to reclaim space. In Data Substrate, the data storage engine is abstracted to work seamlessly with any durable key-value stores, enabling flexibility in choosing the most appropriate storage backend for different workloads or deployment environments.
In the Data Substrate architecture, durability is jointly ensured by the WAL and the storage engine, while availability is maintained through the in-memory TxMap and the data store. A key invariant governs this design: any entry in the TxMap must exist either in the WAL or in the data store, ensuring its durability; conversely, a valid data entry must be present in the TxMap (if dirty), in the data store, or in both (if clean). Concurrency control is handled by CCMap, and very importantly is not the concern of the data store. This decoupling opens the door to significant performance optimizations.
Threading and Cooperative Multitasking
Modern CPUs offer massive parallelism, with machines routinely equipped with dozens or even hundreds of cores. To fully utilize such hardware, software must be architected like a distributed system—even within a single server node. Data Substrate embraces this philosophy from the ground up. As discussed earlier, threads and CCMap shards are the primary units of execution and data ownership, and message passing is the dominant communication model. By avoiding global synchronization and minimizing shared mutable states, this design drastically reduces lock contention and enables highly scalable execution, even within a single physical machine.
Hardware advancements—such as NVMe storage and RDMA networking—have fundamentally shifted the performance ratios of modern computer servers. Newer hardware often offers unprecedented I/O throughput. This contrasts sharply with traditional database designs, where I/O was often the primary bottleneck. In Data Substrate, we fully embrace this shift by adopting cooperative multitasking. This allows threads to issue non-blocking operations and efficiently switch between tasks, minimizing CPU waits and ensuring that each thread remains productive, continuously processing meaningful work.
Fault Tolerance, Recovery, and Transactions
Fault tolerance is a critical aspect of any distributed system, and Data Substrate is designed to gracefully handle both hardware failures and software crashes without sacrificing consistency or availability.
We categorize failures and recovery into two types. The first type involves traditional distributed systems failures, such as data loss due to hardware faults like disk crashes. To mitigate these risks, Data Substrate relies on standard distributed systems techniques—primarily data replication. In cloud environments, many storage services are already replicated for fault tolerance. For instance, AWS EBS and S3 are designed to withstand server and storage failures, allowing us to treat them as effectively fail-safe. In environments where such services are not available—such as on-premises deployments—we can achieve similar level of resilience by replicating data using protocols like Raft. When a compute node fails, orchestration tools like Kubernetes can automatically restart the node elsewhere. In the absence of such tooling, failure detection mechanisms based on lease protocols are well-understood and straightforward to implement.
The second type of failure concerns database transaction execution. For example, a transaction might be interrupted midway due to a node crash, resulting in a situation where the transaction is either uncommitted or its local updates have not yet been fully installed. In such cases, the system must determine the transaction's status and either roll it back or complete its execution. This decision is guided by the WAL, which records the transaction's intent and progress. If the log indicates that the transaction was not committed, all partial updates can be safely discarded. If the commit was recorded but the effects were not fully applied, the system can replay the transaction's updates to bring the state to consistency.
While transaction recovery is a well-studied topic, distributed environments introduce additional complexity—such as handling orphaned locks or coordinating partial transaction states across nodes. We will not go into all the details in this article as a separate paper is under submission to discuss in detail the transaction commit protocols used in Data Substrate. We will sure to discuss this paper in another article when the double blind review period passes.
It's worth noting that by cleanly decoupling the concerns of distributed systems and database transactions, failure handling in Data Substrate becomes much easier to reason about. Historically, the database and distributed systems communities have often taken overlapping but subtly different views on core concepts—such as the definition of consistency and the purpose of logging—which can make discussions around distributed databases unnecessarily confusing. By adopting a "shared everything" approach and treating the system as one large computer, the Data Substrate architecture aims to bridge these perspectives and offer a unified conceptual framework for reasoning about consistency, recovery, and fault tolerance in modern distributed databases.
What about the CAP Theorem?
No discussion of distributed storage systems is complete without addressing the CAP theorem. The theorem famously states that a distributed system cannot simultaneously guarantee consistency, availability, and partition tolerance. However, as ]researchers have pointed out, the theorem's practical implications are most relevant in the presence of network partitions. In normal operation—when the cluster is healthy and there are no partitions—a well-designed distributed system should provide both consistency and availability. Therefore, understanding and clearly defining system behavior during partitions is key to building predictable and resilient distributed databases.
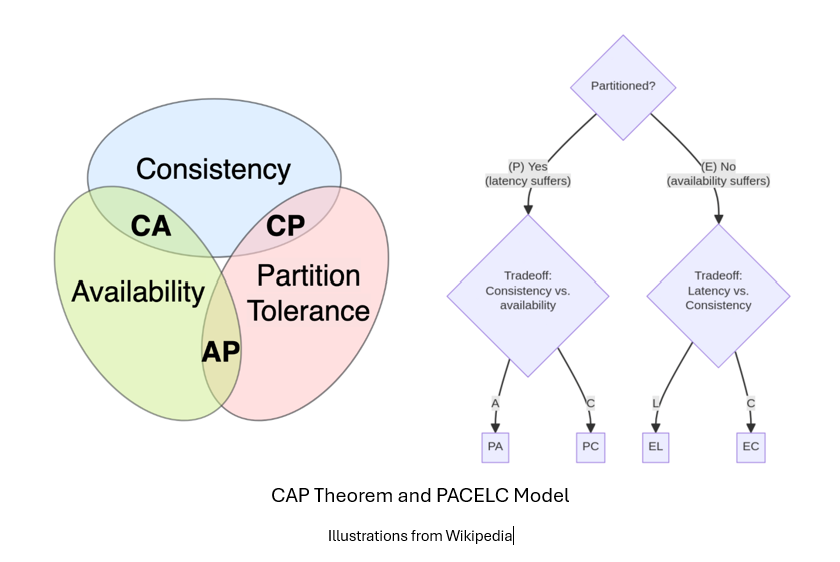
A better understanding of distributed system behavior comes from the PACELC model, which extends the CAP theorem by considering system trade-offs both during and outside of network partitions. PACELC categorizes how a system prioritizes consistency (C) or availability (A) during a Partition (P), and how it balances latency (L) versus consistency (C) Else (E) when no partition exists. Data Substrate generally aligns with the PC/EC category, similar to fully distributed databases like CockroachDB and TiDB. This means that during a partition, the system prioritizes consistency over availability—it will halt database operations if it cannot ensure correctness. Outside of partitions, the system still favors consistency over latency: transactions must be fully committed and durable (e.g., WAL entries replicated and fsync'ed to disk) before acknowledging success to the client. This model ensures strong correctness guarantees, even at the cost of increased latency in normal operations.
Here we'd like to clarify a technical nuance to preempt potential concerns from careful readers. The timestamping mechanism used in Data Substrate allows databases built on it to achieve serializability but not necessarily linearizability. This is due to potential clock skew and the use of time-traveling mechanisms, which may assign commit timestamps that do not strictly reflect real-time order for transactions that are not causally related (of course, the DB is linearlizable for any individual data item). This design is intentional—it reduces transaction aborts and improves throughput while still providing strong, well-understood consistency guarantees. In the context of traditional database workloads, serializability is typically sufficient to ensure correctness, and the so-called strict serializability (i.e. serializability plus real-time ordering) is usually not necessary. That said, like most components in Data Substrate, the timestamping subsystem is modular and can be swapped out—for example, by introducing a centralized time oracle—to support linearizability if required by the application.
While the current implementation of Data Substrate follows a PC/EC configuration, this behavior is not hardwired—it can be adapted to suit different application needs. For example, in high-performance caching scenarios where strict durability and consistency are less critical, the system can be reconfigured to operate in a PA/EL mode, prioritizing availability during partitions and favoring lower latency over strong consistency during normal operation. This flexibility allows Data Substrate to support a wide range of use cases, from transactional databases with strong guarantees to low-latency, high-throughput NoSQL-style workloads, all within a unified architectural framework.
Summary and Future Topics
Data Substrate represents a new architectural approach to building databases for the cloud era, and we believe it has the potential to significantly influence future database design. That said, we do not claim to have invented all the techniques discussed in this article. In fact, nearly all of them—or some variation—have appeared in prior systems or research. What sets Data Substrate apart is the careful and deliberate selection of these techniques, which we believe is the essence of sound architectural design. In a field as mature and intricate as database systems—with over half a century of evolution—it is unrealistic to expect a single, never-before-seen breakthrough to resolve all challenges. The real value lies in the thoughtful integration of proven ideas and the meticulous attention to detail that brings a coherent and effective system to life.
This article has explored several technical aspects of the Data Substrate architecture, but many important topics remain for future discussion. For example, We have not addressed how existing compute engines, such as those from MySQL or MongoDB, can be adapted to run on top of the Data Substrate. We have also not yet explored how this architecture naturally enables cloud-native advantages like Scale to Zero—where compute resources can be fully released during idle periods, incurring only storage costs—and diskless storage -- where object stores like S3 serve as the primary storage layer. These features offer significant reductions in total cost of ownership (TCO) in cloud environments. We will cover some of these topics in later posts.