10X Cost Reduction with Spring Data on EloqKV
· 11 min read

We benchmarked the same Spring Boot caching layer against Redis and EloqKV — with zero code changes. The throughput is comparable. The infrastructure bill is not.
Company news and updates
View All TagsWe benchmarked the same Spring Boot caching layer against Redis and EloqKV — with zero code changes. The throughput is comparable. The infrastructure bill is not.
In the world of high-performance data, many engineering teams hit a "memory wall." As data sets grow, the cost of keeping every single byte in DRAM becomes the primary bottleneck for scaling. This is particularly painful for memory-bound applications, where the performance requirements demand Redis-like speeds, but the sheer volume of data makes the cloud bills unsustainable.
Moving from Redis to EloqKV allows you to shift from expensive, memory-heavy instances to cost-efficient, SSD-optimized infrastructure—all while maintaining the extreme low latency your application requires.
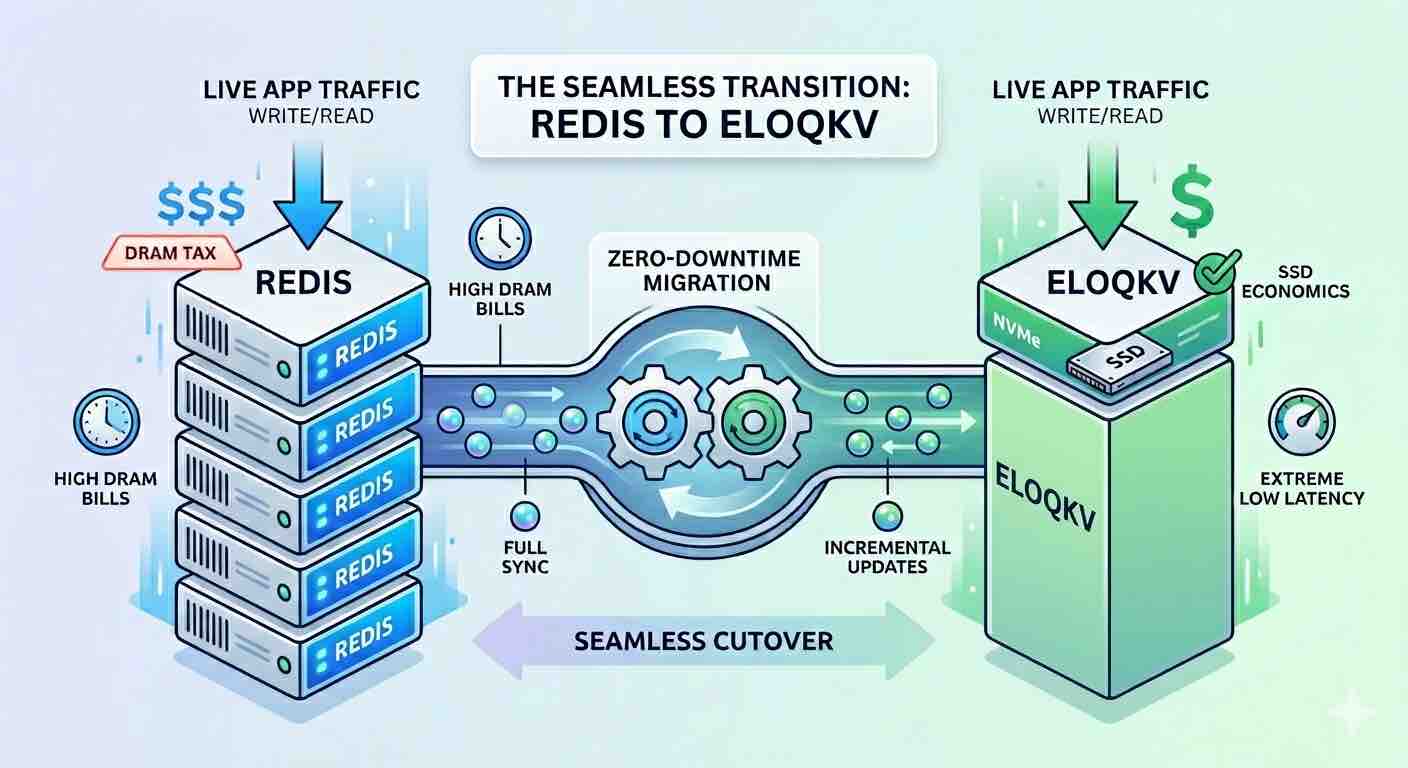
For memory-bound use cases—such as a Feature Store for recommendation systems—the challenge isn't necessarily request volume, but the sheer footprint of user profiles and item embeddings. In a standard Redis setup, you are forced to pay for peak DRAM capacity, even if much of that data isn't accessed every second.
EloqKV breaks this linear cost curve. By utilizing a sophisticated storage engine optimized for NVMe SSDs, it delivers the speed of an in-memory database at the price point of disk storage. This migration doesn't just save money; it allows your business to scale its data footprint without a proportional increase in infrastructure spend.
To ensure a seamless transition with zero downtime, we use RedisShake, a versatile tool that treats EloqKV as a replica of your existing Redis cluster.
The goal of Stage 1 is to mirror your Redis data onto EloqKV without affecting your production environment. RedisShake connects to your source Redis, performs a "Full" sync of the current dataset, and then switches to "Incremental" mode to ship every new write to EloqKV in real-time.
shake.tomlTo bridge the two systems, deploy RedisShake with the following configuration. This setup treats EloqKV as the target writer for all incoming Redis data.
[sync_reader]
cluster = false
address = "redis-production.example.com:6379"
password = "your_source_password"
tls = true
sync_rdb = true # set to false if you don't want to sync rdb
sync_aof = true # set to false if you don't want to sync aof
[redis_writer]
cluster = true
address = "eloqkv-cluster.example.com:6379"
password = "your_target_password"
tls = true
off_reply = false
[filter]
block_command = ["SELECT", "FLUSHALL", "FLUSHDB"]
block_command_group = ["STREAM","GEO","HYPERLOGLOG"]
[advanced]
dir = "/data"
ncpu = 1
status_port = 8084
pprof_port = 9094
log_file = "/data/shake.log"
log_level = "info"
log_interval = 5
log_rotation = true
log_max_size = 512
log_max_age = 7
log_max_backups = 3
log_compress = true
rdb_restore_command_behavior = "rewrite"
pipeline_count_limit = 512
target_redis_max_qps = 30000
empty_db_before_sync = false
target_redis_oom_requeue = true
target_redis_oom_requeue_max_times = 3
target_redis_oom_requeue_delay_ms = 500
io_reconnect = true
io_reconnect_max_times = 100
io_reconnect_delay_ms = 10000
target_redis_writer_shards=4
target_redis_proto_max_bulk_len = 512_000_000
Once the synchronization is stable and replication lag is minimal (usually measured in microseconds), you can begin utilizing EloqKV.
Because recommendation systems are heavily dependent on fast lookups, we switch the Read Traffic first. By pointing your application’s read clients to EloqKV, you can verify that the SSD-based architecture meets your latency requirements under real-world conditions.
Pro Tip: Monitor your p99 latencies during this stage. Most users find that EloqKV’s SSD performance is indistinguishable from Redis DRAM performance for feature lookups, but at a fraction of the cost.
With reads successfully validated on EloqKV, it is time to move the "Source of Truth."
By migrating your memory-bound Feature Store to EloqKV, you effectively decouple your data growth from your DRAM budget. You gain the ability to store 10x the features on the same budget, providing your recommendation models with more context and your business with a lower TCO (Total Cost of Ownership).
The transition is low-risk, the performance remains "extreme," and the SSD-based cost model finally makes large-scale data sets sustainable.
First, a huge thank you to Bohan Zhang and the OpenAI engineering team for sharing their data infrastructure journey. It is a fantastic read, packed with hands-on best practices—from connection pooling with PgBouncer to ruthless query optimization—that any engineer scaling a relational monolith should study.
However, the definition of "scale" is shifting under our feet.
At CES 2026, NVIDIA CEO Jensen Huang delivered a stark warning: the industry is facing a critical shortage of DRAM. While the explosive growth of AI models is the primary driver, there is another massive consumer of memory that often flies under the radar: Caching Services.
Traditionally, caching services like Redis and Valkey are purely memory-based. Even though people have tried to leverage fast SSDs for caching (e.g. Apache KVRocks), for latency-sensitive workloads, DRAM-based solutions remained the only viable solution because SSD-based alternatives often have significant tail latency issues. In mission-critical environments, a latency spike can easily disrupt real-time workflows and render a service unresponsive. Until recently, how to tame tail latency for IO intensive workloads has remained an unsolved challenge.
MinIO has officially moved its Community Edition to a “maintenance-only” release model:
In plain terms: If your production object storage is built on MinIO Community Edition, you are now carrying hidden operational risk and rising maintenance costs.
PostgreSQL and DuckDB have become the go-to databases for developers everywhere. Postgres is the default choice for transactional workloads, while DuckDB has quietly taken over the analytics world. Both are simple, fast, and easy to use. You can spin them up in seconds, run them anywhere, and they "just work." For most use cases, that's more than enough. But it's worth noting that both are single-node systems at heart. They can scale up, but when you hit the limits of one machine, you have to look elsewhere to migrate your infrastructure.
Many people now argue that single-node databases are enough for almost everything. Hardware has become so powerful that even massive workloads can often fit on one beefy machine. OpenAI recently discussed how their main database runs on a single-writer PostgreSQL setup. Just one node handling all the writes, with many read replicas to scale out read traffic. That's a bold design, and it suggests that maybe we no longer need complicated distributed databases because modern CPUs, SSDs, and memory are making scale-out architectures look like overkill.
In this artcle, we discuss how we reached this state in the database landscape, and disucss the future for scalable databases. We draw many inspirations from history, and we believe that there is a very bright future for database community going forward as we entering the new era of growth and prosperity.
The internet (or at least the IT community) had a field day when a couple of blog posts claimed you could replace Redis and Kafka with PostgreSQL. "Redis is fast, I'll cache in Postgres" and "Kafka is fast -- I'll use Postgres" have gotten much attention on HackerNews here and here, and on Reddit here and here. Obviously, some of the claims in the posts got roasted on HN and Reddit for suggesting you could replace Redis or Kafka with PostgreSQL. Many people (correctly) pointed out that the benchmarks were far from properly set up, and the workloads were non-typical. Some of the Kafka people also posted long articles to clarify what Kafka is designed for and why it is not hard to use. But, on the flip side, many of the posts also (correctly) preached a valid point: keeping fewer moving parts matters, and using the right tool for the job matters even more.
Cloud native databases are designed from the ground up to embrace core cloud principles: distributed architecture, automatic scalability, high availability, and elasticity. A prominent example is Amazon Aurora, which established the prevailing paradigm for online databases by championing the decoupling of compute and storage. This architecture allows the compute layer (responsible for query and transaction processing) and the storage layer (handling data persistence) to scale independently. As a result, database users benefit from granular resource allocation, cost efficiency through pay-per-use pricing, flexibility in hardware choices, and improved resilience by isolating persistent data from ephemeral compute instances.
In this blog post, we re-examine this decoupled architecture through the lens of cloud storage mediums. We argue that this prevailing model is at a turning point, poised to be reshaped by the emerging synergy between instance-level, volatile NVMe and highly durable object storage.
On October 20, 2025, AWS experienced a major disruption across multiple services in the us-east-1 region. According to AWS Health Status, various compute, storage, and networking services were impacted simultaneously. For many teams running OLTP databases on instances backed by local NVMe, this was not just a downtime problem-it was a data durability nightmare.
Online databases are the backbone of interactive applications. Despite coming in many different types, online databases are all engineered for low-latency, high-throughput CRUD operations. At EloqData, we use the universal Data Substrate to build online databases for any model—from key-value and tables to JSON documents and vectors. In this post, we explore one of our core engineering practices for future online databases.
In the previous article, we discussed the details of some of the architecture design of Data Substrate. In this article, we continue the discussion and elaborate on why we made these design choices and how these choices affect the resulting database solutions we built.
In this article, we dive deeper into the technical foundations of Data Substrate—highlighting the key design decisions, abstractions, and architectural choices that set it apart from both classical and modern distributed databases.
At EloqData, we've developed Data Substrate—a database architecture designed to meet the unprecedented demands of modern applications in the AI age. Unlike traditional database systems that struggle with the scale and complexity of AI workloads, Data Substrate reimagines the database as a unified, distributed computer where memory, compute, logging, and storage are fully decoupled yet globally addressable.
At the recent Data Stream Summit 2025, Hubert Zhang, CTO of EloqData, delivered a talk on building elastic, agentic AI data pipelines using Apache Pulsar and EloqDoc.
In the previous blog, we discussed the future database foundation for Agentic AI Applications. In this blog we will simplify the agentic application and use EloqKV as data store to explore EloqKV's decoupled architecture.
We have recently open sourced our three products: EloqKV, EloqSQL, and EloqDoc. These offerings reflect our commitment to addressing the evolving demands of modern data infrastructure, particularly as we enter an era dominated by powerful, autonomous AI systems.
LLM-powered Artificial Intelligence (AI) applications are driving transformative changes across industries, from healthcare to finance and beyond. We are rapidly entering the Agentic Application Age, an era where autonomous, AI-driven agents not only assist but actively make decisions, manage tasks, and optimize outcomes independently.
However, the backbone of these applications—the data infrastructure—faces immense challenges in scalability, consistency, and performance. In this post, we explore the critical limitations of current solutions and introduce EloqData’s innovative approach specifically designed to address these challenges. We also share our vision for an AI-native database, purpose-built to empower the Agentic Application Age, paving the way for smarter, more autonomous, and responsive AI applications in the future.
We have recently introduced EloqKV, our distributed database product built on a cutting-edge architecture known as Data Substrate. Over the past several years, the EloqData team has worked tirelessly to develop this software, ensuring it meets the highest standards of performance and scalability. One key detail we’d like to share is that the majority of EloqKV’s codebase was written in C++.
In the previous blog, we discussed the durable feature of EloqKV and benchmarked the write performance of EloqKV with the Write-Ahead-Log enabled. In this blog, we will continue to explore the transaction capabilities of EloqKV and benchmark the performance of distributed atomic operations using the Redis MULTI EXEC commands.
In this blog post, we introduce our transformative concept Data Substrate. Data Substrate abstracts core functionality in online transactional databases (OLTP) by providing a unified layer for CRUD operations. A database built on this unified layer is modular: a database module is optional, can be replaced and can scale up/out independently of other modules.